LARGE LANGUAGE MODELING (LLM)
What are large language models (LLMs)?
A large language model (LLM) is a type of artificial intelligence (AI) algorithm that uses deep learning techniques and massively large data sets to understand, summarize, generate and predict new content. The term generative AI also is closely connected with LLMs, which are, in fact, a type of generative AI that has been specifically architected to help generate text-based content.
Over millennia, humans developed spoken languages to communicate. Language is at the core of all forms of human and technological communications; it provides the words, semantics and grammar needed to convey ideas and concepts. In the AI world, a language model serves a similar purpose, providing a basis to communicate and generate new concepts.
The first AI language models trace their roots to the earliest days of AI. The Eliza language model debuted in 1966 at MIT and is one of the earliest examples of an AI language model. All language models are first trained on a set of data, and then they make use of various techniques to infer relationships and then generate new content based on the trained data. Language models are commonly used in natural language processing (NLP) applications where a user inputs a query in natural language to generate a result.
An LLM is the evolution of the language model concept in AI that dramatically expands the data used for training and inference. In turn, it provides a massive increase in the capabilities of the AI model. While there isn't a universally accepted figure for how large the data set for training needs to be, an LLM typically has at least one billion or more parameters. Parameters are a machine learning term for the variables present in the model on which it was trained that can be used to infer new content.

1. What is Language Modeling?
Language Modeling is a pivotal technique within the realm of natural language processing (NLP), utilized for predicting subsequent words in a sentence or sequence based on context and prior words. Its primary function is to decipher the structure, grammar, and meaning embedded within a given text.
Typically, Language Modeling harnesses deep learning algorithms like recurrent neural networks (RNNs) or transformer models, which are trained on extensive datasets comprising text from diverse sources. During training, the model is exposed to input text, and its parameters are optimized to accurately predict the next word or sequence of words within a specific context.
The significance of Language Modeling spans across various NLP applications, including machine translation, sentiment analysis, text generation, speech recognition, and question answering. By enabling machines to comprehend and generate human-like text, it enriches the capabilities of chatbots, virtual assistants, and other AI-driven systems. Additionally, Language Modeling facilitates data-driven decision-making and insights extraction from voluminous textual data.
2. What are the applications if we can model the language?
1. Machine Translation:
Enhancing the accuracy and fluency of machine translation systems by generating contextually appropriate translations.
2. Text Generation:
Enabling the creation of coherent and contextually accurate text for applications such as content creation, chatbot responses, and automatic report writing.

3. Speech Recognition:
Aiding in precise speech recognition by predicting the most probable sequence of words given the audio input.
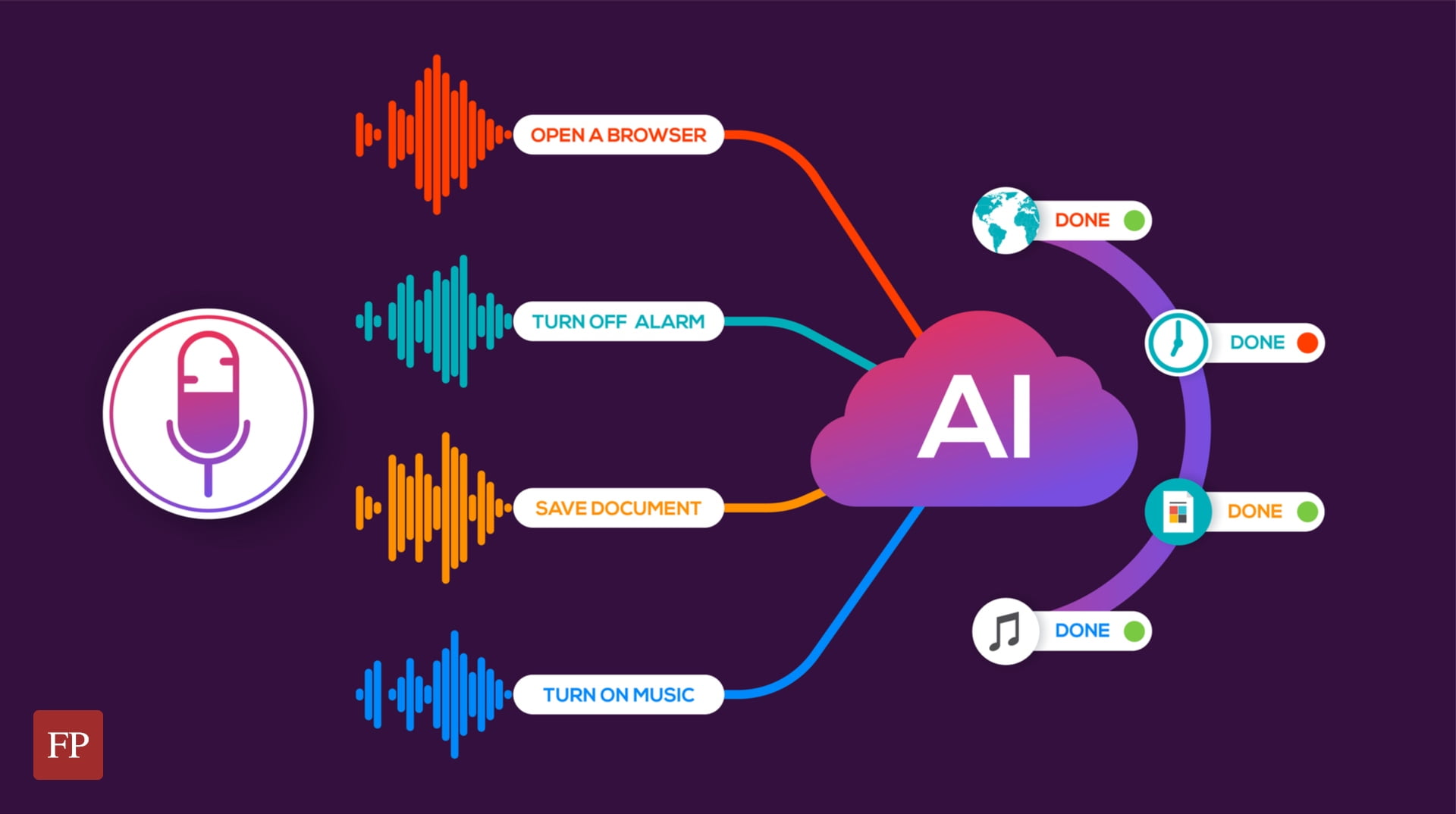
4. Question Answering:
Constructing question answering systems capable of understanding natural language queries and furnishing relevant answers.

5. Named Entity Recognition:
Assisting in the identification and classification of named entities (e.g., person names, locations, organizations) within a given text.
6. Natural language processing (NLP):
Natural Language Processing (NLP) is a field of artificial intelligence that focuses on the interaction between humans and machines using natural language.Large language models are a key component of NLP, as they can be used to understand and generate natural language. This makes them incredibly useful for a wide range of applications, including challenges in natural language processing, from chatbots and virtual assistants to sentiment analysis and content creation.

7. Chatbots and virtual assistants:
One of the most popular LLM applications is the development of chatbots and virtual assistants. These models can understand how people ask questions and give answers that are very similar to what a person would say.This has enabled businesses to improve their customer service by providing 24/7 support to their customers without the need for human intervention.LLM Applications can be trained on a vast amount of text data to improve their performance in understanding the nuances of natural language. They can also be fine-tuned to cater to specific domains, such as finance, healthcare, and education, to provide personalized responses to queries.

Related Technologies and Terms in Language Modeling include:
Transformer Models: Such as BERT (Bidirectional Encoder Representations from Transformers), revolutionize language modeling by capturing long-range dependencies and enhancing contextual word and sentence representations.
Recurrent Neural Networks (RNNs): A class of neural networks adept at processing sequences of inputs efficiently, owing to their internal memory.
Word Embeddings: Representations of words as dense vectors in a continuous space, facilitating language comprehension and modeling. Examples include Word2Vec and GloVe.
Incorporating Language Modeling into workflows empowers businesses to leverage textual data for informed decision-making, bolster data engineering and machine learning practices, and gain a competitive edge in the AI-driven business landscape.
3. How do you model a language?
Modeling a language involves creating computational representations of its structure, syntax, semantics, and usage patterns. The goal is to develop a system that can understand and generate human-like text. Here's a general overview of how language modeling is typically approached:
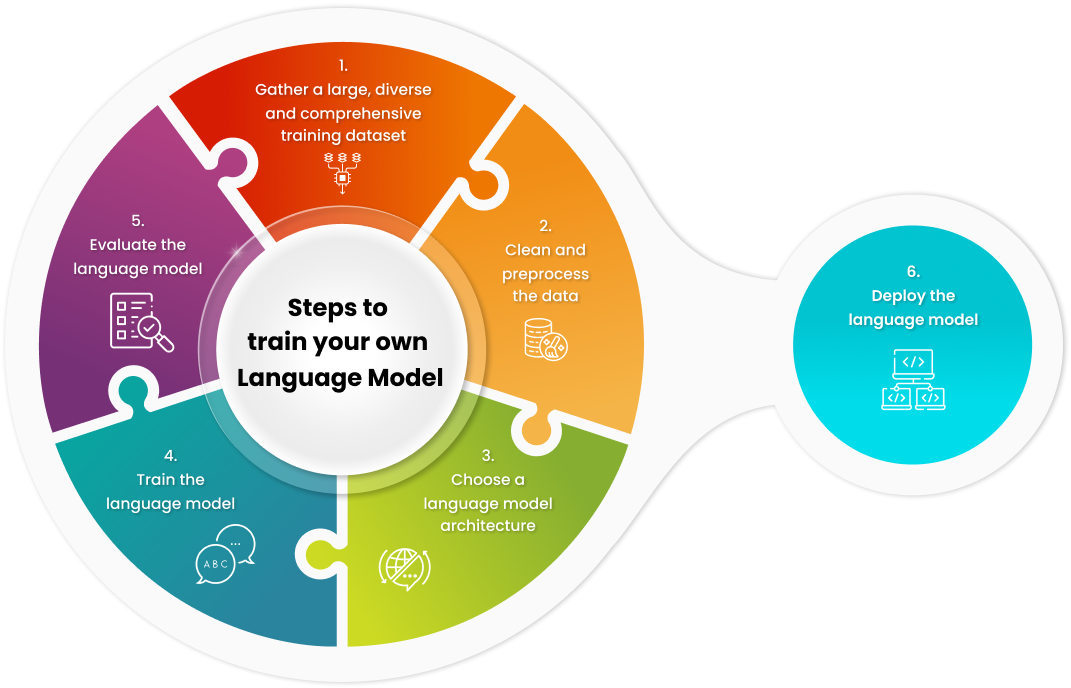
1. Data Collection: The first step in language modeling is gathering a large dataset of text in the target language. This corpus of text serves as the training data for the language model. The dataset can be sourced from various text sources such as books, articles, websites, social media, or any other text repositories.
2. Preprocessing: Before training the language model, the text data undergoes preprocessing. This step involves tasks such as tokenization (breaking text into words or subwords), lowercasing, removing punctuation, handling special characters, and possibly filtering out irrelevant or noisy text.
3. Choosing a Model Architecture: Language models can be built using various architectures, such as recurrent neural networks (RNNs), long short-term memory networks (LSTMs), gated recurrent units (GRUs), or transformer models. The choice of architecture depends on factors like the size of the dataset, computational resources available, and the specific requirements of the task.
4. Training: Once the data is preprocessed and the model architecture is selected, the language model is trained on the text dataset. During training, the model learns to predict the next word or sequence of words in a sentence given the context of the preceding words. This process involves adjusting the model's parameters (weights and biases) using optimization algorithms like stochastic gradient descent (SGD) or Adam to minimize the prediction error.
5. Evaluation: After training, the language model is evaluated on a separate validation or test dataset to assess its performance. Evaluation metrics such as perplexity (a measure of how well the model predicts the data) or accuracy may be used to quantify the model's performance.
6. Fine-Tuning (Optional): In some cases, pretrained language models can be fine-tuned on domain-specific or task-specific datasets to improve their performance on specific tasks such as sentiment analysis, named entity recognition, or machine translation.
7. Deployment: Once trained and evaluated, the language model can be deployed for use in various NLP applications. This may involve integrating the model into a larger system or application, such as a chatbot, virtual assistant, or machine translation service.
Overall, modeling a language is a complex process that involves collecting, preprocessing, training, evaluating, and deploying computational representations of linguistic structures and patterns. The effectiveness of a language model depends on factors such as the quality and size of the training data, the choice of model architecture, and the optimization techniques used during training.


Comments
Post a Comment