Navigating the GenAI Frontier: Transformers, GPT, and the Path to Accelerated Innovation
Navigating the GenAI Frontier: Transformers, GPT, and the Path to Accelerated Innovation

Navigating the Gen AI Frontier: Exploring Cutting-Edge Technologies and Innovation
In today's ever-evolving digital landscape, the rise of Generation AI (Gen AI) brings forth both challenges and opportunities for businesses aiming to remain at the forefront of innovation. With breakthroughs in natural language processing and artificial intelligence, revolutionary technologies like Transformers, ChatGPT, GPT-1, Attention Mechanism, and BERT are fundamentally transforming how we engage with data and make strategic decisions.
In this article, we embark on a journey to unravel the profound impact of these cutting-edge technologies on the future of innovation, equipping businesses with the essential tools to thrive in the Gen AI era. Let's delve into the realm of Transformers, GPT models, and the accelerated path to innovation in the digital age.
Transformers: Pioneering Intelligent Data Processing
At the heart of the Gen AI revolution lies Transformers, a paradigm-shifting architecture that has redefined the landscape of natural language processing and machine learning. With its attention mechanism and self-attention mechanism, Transformers excel at capturing long-range dependencies within data, enabling more nuanced understanding and context-aware processing.
ChatGPT and GPT-1: Empowering Conversational AI
Enter ChatGPT and GPT-1, two groundbreaking iterations of the Generative Pre-trained Transformer model. These models have transcended traditional limitations, empowering businesses to deploy conversational AI solutions that engage users with unprecedented levels of naturalness and coherence. From customer service chatbots to virtual assistants, ChatGPT and GPT-1 are revolutionizing human-computer interaction and customer experience.
Attention Mechanism: Focusing on Relevance
In the realm of machine learning, attention mechanism has emerged as a pivotal component for enhancing model performance. By dynamically allocating attention to relevant parts of input data, attention mechanisms enable models to focus on crucial information, leading to more accurate predictions and insights. This capability is invaluable in applications ranging from language translation to image recognition, where relevance and context are paramount.
BERT: Unveiling Contextual Understanding
Bidirectional Encoder Representations from Transformers (BERT) stands as a milestone in natural language understanding, introducing contextualized word embeddings that capture the nuances of language more effectively. By considering the entire context of a word within a sentence, BERT surpasses previous models in tasks such as sentiment analysis, question answering, and semantic similarity evaluation, setting new benchmarks for language understanding models.
Accelerated Innovation in the Gen AI Era
As businesses navigate the Gen AI frontier, leveraging these transformative technologies becomes imperative for sustained success and competitiveness. By harnessing the power of Transformers, GPT models, attention mechanisms, and BERT, organizations can unlock unprecedented opportunities for innovation across diverse domains. From personalized recommendation systems to predictive analytics and autonomous decision-making, the possibilities are limitless.
Conclusion
The Gen AI frontier heralds a new era of innovation and disruption, driven by the convergence of advanced technologies and human ingenuity. By embracing the transformative potential of Transformers, GPT models, attention mechanisms, and BERT, businesses can chart a course towards accelerated innovation and sustainable growth in the digital age. As we continue to explore the depths of the Gen AI landscape, let us seize the opportunities that lie ahead and pioneer a future defined by intelligent collaboration between man and machine.
Introduction:

Envision a world where machines compose music akin to your favorite artist, craft paintings reminiscent of renowned masters, or even write code rivaling the brilliance of computer pioneers. Such possibilities are no longer confined to the realm of imagination but are becoming reality, thanks to Generative AI—a cutting-edge technology that generates novel content.
Generative AI distinguishes itself from traditional AI by its ability to learn and perform a myriad of tasks, heralding an era of unprecedented creativity and innovation. However, amidst the excitement, it's imperative to approach this technology with caution and responsibility.
Much like guardrails that ensure safe passage on roads, Generative AI necessitates guidelines to navigate potential pitfalls. From the dissemination of misinformation to the creation of manipulated media, there are inherent risks that must be addressed proactively. In this blog, we delve into the importance of establishing robust guidelines to ensure the safe and ethical utilization of Generative AI, drawing insights from real-world examples and ongoing research.
Key Points to Remember:
- Fascination and Risks: While Generative AI is undeniably captivating, it also poses inherent risks that demand careful consideration.
- Necessity of Guidelines: Establishing clear guidelines is essential to steer the safe and responsible usage of Generative AI, akin to guardrails guiding vehicular safety.
- Mitigating Risks: Measures such as meticulous selection of training data, leveraging technology for oversight, incorporating human checks, and prioritizing transparency can mitigate risks associated with Generative AI.
- Continuous Learning: The landscape of Generative AI is dynamic, necessitating continual learning and adaptation of guidelines to ensure ongoing safety and ethical usage.
- Collaborative Efforts: Harnessing the transformative potential of Generative AI for positive impact requires collaborative endeavors involving stakeholders from diverse domains.
1. Historical Context: seq2seq paper and nmt by joint learning to align & translate paper
Historical Context before the Evolution of Transformers
Before the emergence of Transformers, the landscape of neural network architectures underwent significant evolution up to 2013. During this time, a variety of architectures gained popularity, including Artificial Neural Networks (ANN), Convolutional Neural Networks (CNN), and Recurrent Neural Networks (RNN). These architectures demonstrated effectiveness in handling diverse data types such as tabular, image, and sequential data.
In 2014, the introduction of the "Sequence to Sequence Learning with Neural Networks" paper marked a pivotal moment. It presented a groundbreaking approach to sequence learning using Deep Neural Networks (DNNs). While DNNs excelled at complex tasks, they struggled with sequence-to-sequence mappings. The authors proposed an end-to-end solution that relied on multilayered Long Short-Term Memory (LSTM) networks to map input sequences to fixed-dimensional vectors and decode target sequences.
The paper also revealed that the LSTM learned meaningful phrase and sentence representations, sensitive to word order and relatively invariant to voice variations.
This paper proposed the Encoder-Decoder Architecture, specifically tailored for tasks like machine translation. Unlike traditional models with fixed-length mappings, Seq2Seq models embraced variable-length sequences, making them suitable for translation, summarization, and question answering tasks.
Central to the Seq2Seq model is the encoder-decoder architecture. The encoder processes input sequences, preserving hidden states to generate a context vector, representing the entire sentence. Subsequently, the decoder utilizes this context vector to generate output sequences token by token. RNN/LSTM cells were commonly employed in both encoder and decoder due to their sequential dependency capturing abilities. However, despite its capabilities with shorter sentences, this architecture struggled with longer sequences due to information loss in the fixed-length context vector.
In 2015, the "Neural Machine Translation by Joint Learning to Align and Translate" paper introduced the attention mechanism to address these shortcomings. Unlike previous models, attention allowed dynamic focus on different parts of the source sentence while translating. By adjusting attention weights, the model could assign importance to each word differently, leading to more accurate translations, especially with longer input sentences. Despite these improvements, the architecture's sequential training posed challenges, limiting its scalability and hindering techniques like transfer learning and fine-tuning.
The use of LSTM units in the architecture presents a significant challenge due to the sequential training process. Because only one token can be processed at a time as input to the encoder, training times are notably slow. As a result, efficiently training the model with large datasets becomes impractical. This limitation hampers the application of techniques such as transfer learning, which relies on leveraging pretrained models to enhance performance on new tasks. Additionally, the slow training process impedes fine-tuning, which involves further training pretrained models on task-specific data. This necessitated training models from scratch for each task, demanding significant time, effort, and data.
To provide a comprehensive historical context for the Seq2Seq and NMT (Neural Machine Translation) by Joint Learning to Align & Translate papers, we need to delve into the landscape of machine translation and the advancements in neural network architectures leading up to these seminal works.
Pre-Neural Machine Translation Era:
Before the advent of neural networks, statistical machine translation (SMT) dominated the field. SMT systems relied on complex statistical models and hand-crafted features to translate text from one language to another. While effective to some extent, SMT systems often struggled with handling long-range dependencies and capturing semantic nuances, leading to translations that were less fluent and natural.
The Rise of Neural Networks in Machine Translation:
The breakthrough in using neural networks for machine translation can be traced back to the introduction of the encoder-decoder architecture, which formed the basis of Seq2Seq models. The Seq2Seq model, introduced by Sutskever et al. in the 2014 paper "Sequence to Sequence Learning with Neural Networks", revolutionized machine translation by employing recurrent neural networks (RNNs) to encode a source sentence into a fixed-length vector representation, which is then decoded by another RNN to generate the target translation.
The Seq2Seq Paper:
In their landmark paper, Sutskever et al. proposed the Seq2Seq model, demonstrating its effectiveness in various sequence-to-sequence tasks, including machine translation. The key innovation of the Seq2Seq model lies in its ability to handle variable-length input and output sequences, making it suitable for tasks like translation where the length of sentences may vary.
The Seq2Seq model's architecture allowed it to capture the semantic meaning of the source sentence and generate fluent translations, significantly outperforming traditional SMT systems. However, Seq2Seq models faced challenges in handling long-range dependencies and alignment between words in the source and target languages.
NMT by Joint Learning to Align & Translate Paper:
To address the alignment issue in Seq2Seq models and further improve translation quality, Bahdanau et al. proposed the NMT (Neural Machine Translation) by Joint Learning to Align & Translate model in their 2014 paper. This model introduced the attention mechanism, which enables the model to focus on different parts of the source sentence dynamically while generating the translation.
The attention mechanism allows the model to align words in the source and target sentences more effectively, mitigating the issue of long-range dependencies and improving translation quality significantly. By jointly learning to align and translate, the NMT model surpassed the performance of previous Seq2Seq approaches and set a new standard for machine translation quality.
Impact and Legacy:
The Seq2Seq and NMT papers marked a paradigm shift in machine translation, paving the way for the dominance of neural network-based approaches over traditional statistical methods. These papers not only revolutionized machine translation but also influenced research in various other natural language processing tasks, inspiring numerous follow-up works and advancements in neural network architectures.
The attention mechanism introduced in the NMT paper became a fundamental building block in many sequence-to-sequence models, leading to further improvements in various NLP tasks beyond machine translation.
In conclusion, the Seq2Seq and NMT papers represent pivotal milestones in the evolution of machine translation, showcasing the power of neural networks and attention mechanisms in capturing complex linguistic patterns and generating high-quality translations. These papers laid the foundation for modern approaches to machine translation and continue to shape research in the field of natural language processing.
2. Introduction to Transformers (Paper: Attention is all you need)
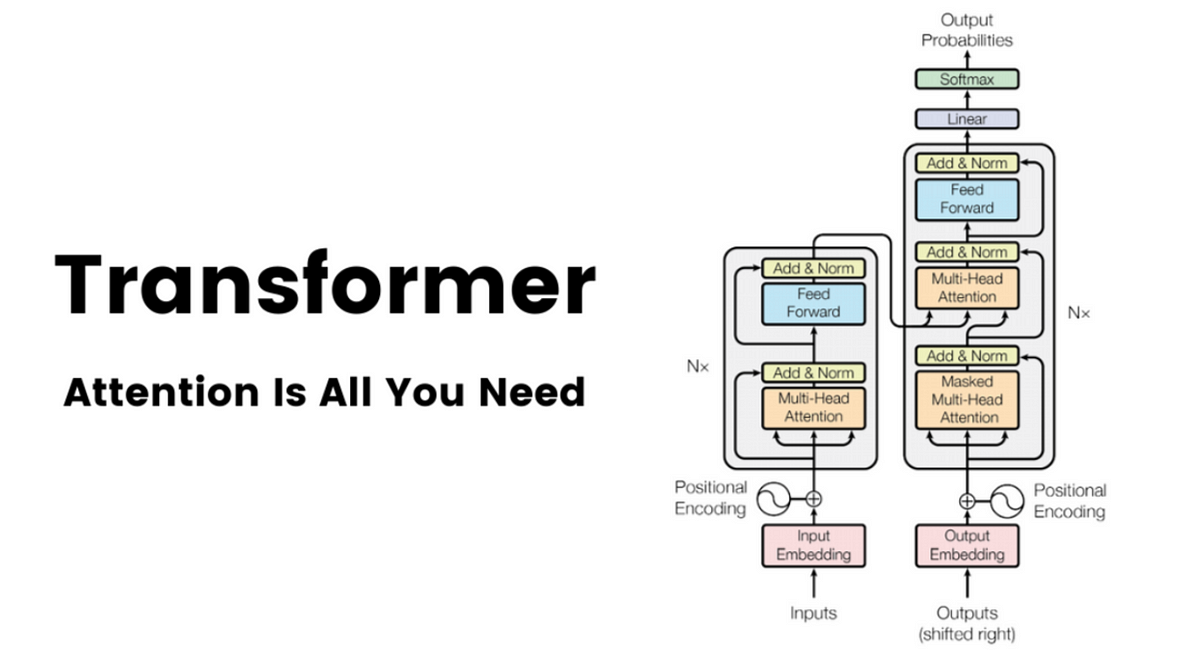
The article "Attention is All You Need" was a breakthrough paper in the field of natural language processing (NLP) that introduced the Transformer architecture.
Published by researchers Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin in June 2017, this opened up possibilities for LLM which never existed before.
Here are the key aspects of the paper:
- Motivation: There were huge limitations of existing sequence-to-sequence models, particularly in handling long-range dependencies and parallelization.
- Transformer Architecture: The Transformer architecture was based solely on attention mechanisms and eschews the recurrent or convolutional layers traditionally used in sequence-based models. It introduces the concept of self-attention, allowing the model to weigh different parts of the input sequence differently based on their relevance to the current step.
- Self-Attention Mechanism: Self-attention allows each position in the input sequence to focus on different parts of the sequence, enabling the model to capture long-range dependencies efficiently. The attention mechanism computes a set of attention weights for each position in the input sequence, determining the importance of other positions.
- Multi-Head Attention: The authors introduced multi-head attention, where the model learns different attention weights for different aspects or "heads" of the input data. This enables the model to capture various types of information simultaneously.
- Positional Encoding: Since the Transformer lacks the inherent sequential structure found in recurrent networks, positional encodings are added to the input embeddings to provide information about the position of each element in the sequence.
- Feedforward Networks and Layer Normalization: The Transformer includes feedforward networks and layer normalization to further enhance the model's capacity to capture complex patterns.
- Encoder and Decoder Stacks: The Transformer consists of multiple layers of both encoder and decoder stacks, allowing it to process input sequences and generate output sequences.
- Attention is Computationally Efficient: The attention mechanism in the Transformer is highly parallelizable, making it computationally more efficient than traditional sequential models, especially for long sequences.
- Applications: The Transformer architecture has become the foundation for various state-of-the-art NLP models, including OpenAI's GPT series and BERT, among others.
"Attention is All You Need" revolutionized the field of NLP by demonstrating the effectiveness of attention mechanisms in capturing contextual information across sequences. The Transformer architecture has since become a cornerstone in the development of powerful and efficient deep-learning models for natural language understanding and generation.
3. Why Transformers?
Advantages of Transformers:
1.Parallelization: Transformers allow for parallelization of computation across input sequences, enabling faster training and better scalability compared to traditional recurrent models. This parallelization significantly enhances efficiency, especially for large-scale datasets.
2.Long-range Dependencies: Unlike recurrent neural networks (RNNs), which suffer from vanishing or exploding gradients over long sequences, Transformers capture long-range dependencies effectively through self-attention mechanisms. This capability makes them well-suited for tasks requiring understanding of context over extended spans of text.
3.Attention Mechanism: The attention mechanism in Transformers enables dynamic focus on different parts of the input, allowing the model to assign varying importance to different tokens. This flexibility enhances performance, particularly in tasks like machine translation or summarization.
4.Transfer Learning: Transformers facilitate transfer learning in natural language processing (NLP) by leveraging pre-trained models. These models can be fine-tuned on task-specific data, leading to improved performance with reduced computational resources and training time.
5.Scalability: Transformers exhibit excellent scalability, enabling efficient training on large datasets. This scalability is essential for handling real-world applications with extensive data requirements, such as language translation or document summarization.
6.Effective Handling of Long-Range Dependencies: Unlike traditional recurrent neural networks (RNNs) or convolutional neural networks (CNNs), Transformers excel at capturing long-range dependencies in sequences. This capability is crucial for tasks such as language translation, where understanding context across an entire sentence or document is essential.
7.Flexibility and Adaptability: Transformers are highly versatile and can be applied to various NLP tasks, including machine translation, text summarization, sentiment analysis, question answering, and more. Their modular architecture allows for easy customization and adaptation to different domains and languages.
8.State-of-the-Art Performance: Transformers have consistently achieved state-of-the-art performance on benchmark NLP tasks and competitions. Their ability to capture complex linguistic patterns and semantics has propelled them to the forefront of NLP research and applications.
Disadvantages of Transformers:
1.Computational Complexity: The self-attention mechanism in Transformers involves computing pairwise attention scores for all tokens in the sequence, resulting in quadratic time complexity with respect to the sequence length. This computational overhead can be prohibitive for very long sequences.
2.Limited Context Window: Transformers are constrained by the maximum sequence length they can effectively process due to memory limitations. This limitation restricts their ability to capture context over very long texts or documents, leading to potential information loss.
3.Training Data Requirements: Like other deep learning models, Transformers require substantial amounts of annotated training data to generalize effectively. Acquiring and curating such datasets can be time-consuming and expensive, particularly for specialized domains or languages with limited resources.
4.Interpretability: Despite their effectiveness, Transformers lack interpretability compared to simpler models like logistic regression or decision trees. Understanding the inner workings of Transformer-based models and interpreting their predictions can be challenging, especially for complex tasks or high-dimensional input data.
5.Overfitting: Transformers, like other deep learning models, are susceptible to overfitting, especially when trained on small datasets or with inadequate regularization techniques. Overfitting can lead to poor generalization performance on unseen data, necessitating careful model validation and regularization strategies.
4.Explain the working of each transformer component.
1,Input Embeddings:
- The input to a Transformer model consists of a sequence of tokens, typically represented as one-hot encoded vectors or learned embeddings.
- These token embeddings are transformed into continuous vector representations, capturing semantic information about each token's meaning and context in the input sequence.
2.Positional Encodings:
- Transformers do not inherently understand the sequential order of tokens in the input sequence since they lack recurrence or convolution.
- Positional encodings are added to the token embeddings to convey the position or order of tokens in the sequence.
- These positional encodings are typically sinusoidal functions of different frequencies and phases, allowing the model to differentiate between tokens based on their positions.
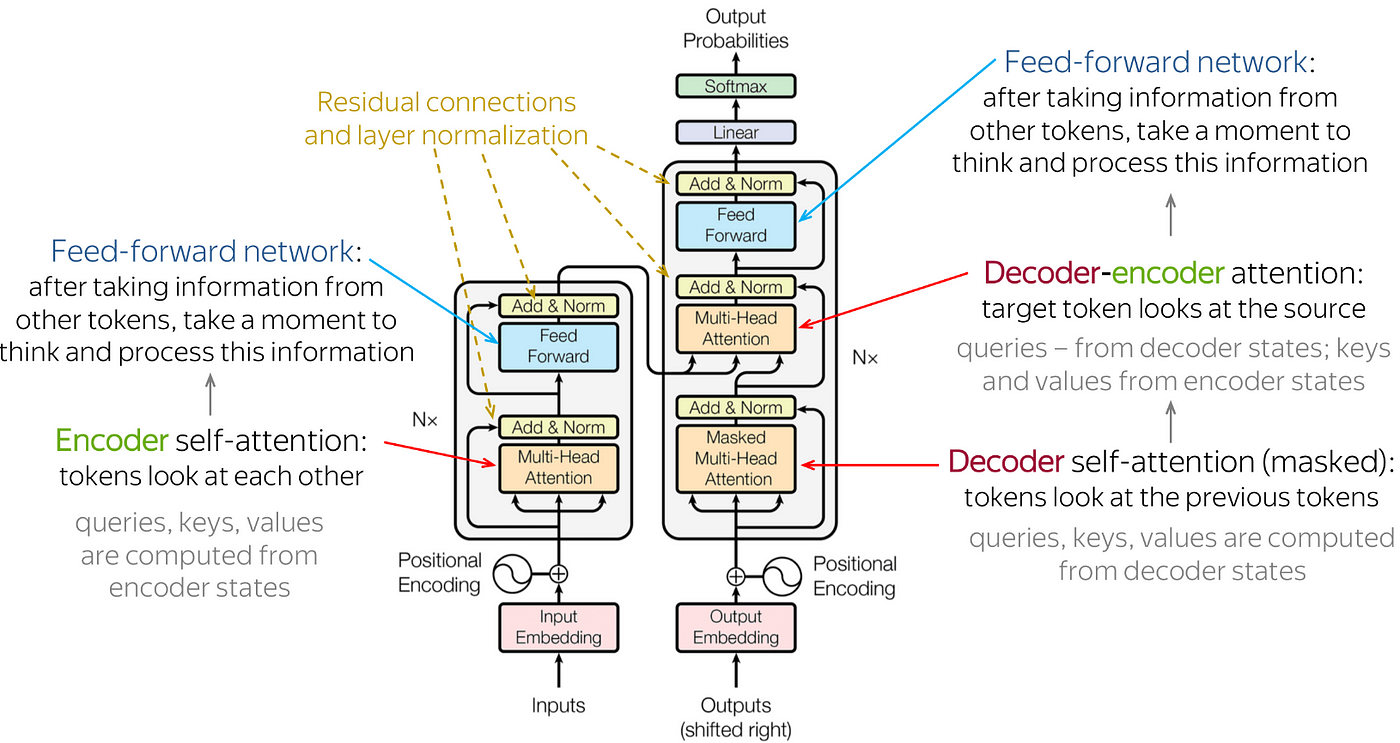
3.Self-Attention Mechanism:
- The self-attention mechanism is the core component of a Transformer model, responsible for capturing dependencies between different tokens in the input sequence.
- For each token in the sequence, self-attention computes a weighted sum of all other tokens' embeddings, where the weights are determined by the similarity (or attention) between the token and other tokens.
- This mechanism allows each token to attend to relevant information from all other tokens in the sequence, capturing long-range dependencies and contextual information effectively.
4.Multi-Head Attention:
- To enhance the expressive power of self-attention, Transformers typically employ multi-head attention mechanisms.
- In multi-head attention, the input embeddings are linearly projected into multiple smaller-dimensional spaces, known as heads.
- Self-attention is then computed independently for each head, allowing the model to attend to different parts of the input sequence simultaneously.
- The outputs from all heads are concatenated and linearly transformed to produce the final attention output.
5.Feed-Forward Neural Networks (FFNN):
- After self-attention, the output is passed through a feed-forward neural network (FFNN) layer independently for each token.
- The FFNN layer consists of two linear transformations followed by a non-linear activation function (e.g., ReLU).
- This layer introduces non-linearity and allows the model to capture complex patterns and relationships in the data.
6.Residual Connections and Layer Normalization:
- To address the issue of vanishing or exploding gradients during training, Transformers use residual connections and layer normalization.
- Residual connections add the input embeddings to the output of each sub-layer (e.g., self-attention or FFNN), allowing gradients to flow more easily during training.
- Layer normalization is applied after each sub-layer, normalizing the activations to stabilize training and improve convergence.
7.Encoder-Decoder Architecture:
- In tasks like machine translation or text generation, Transformers typically employ an encoder-decoder architecture.
- The encoder processes the input sequence and generates a contextualized representation for each token.
- The decoder uses the encoder's outputs and generates the output sequence token by token, attending to relevant parts of the input sequence using cross-attention mechanisms.
- Output from decoder is a vector of length of input tokens
- Feed into linear/fully connected layer + softmax
- Map output to set of output prediction
- Convert prediction into probability over possible words like multi-class classification
By combining these components, Transformers achieve state-of-the-art performance in various natural language processing tasks, effectively capturing long-range dependencies and contextual information in input sequences.
5. How is GPT-1 trained from Scratch? (Take Reference from BERT and GPT-1 Paper)
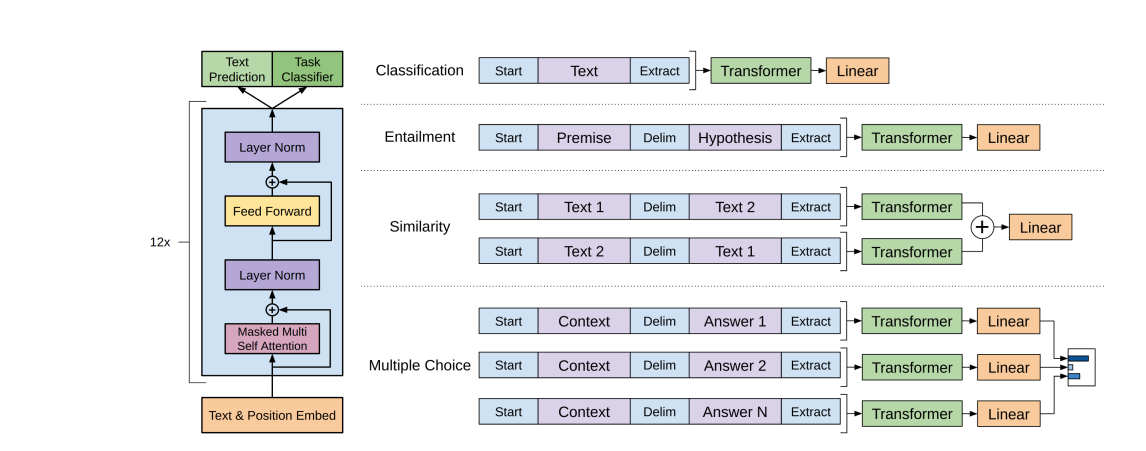
Training GPT-1 from scratch involves several key steps, drawing from the methods outlined in the original BERT and GPT-1 papers. Here's an overview of the training process:
1.Architecture Specification:
- Define the architecture of GPT-1, specifying the number of layers, hidden units, attention heads, and other hyperparameters. GPT-1 consists of a multi-layer stack of Transformer encoder blocks.
2.Preprocessing:
- Preprocess the training data to tokenize text into subword units or tokens. This involves techniques like Byte Pair Encoding (BPE) or WordPiece tokenization, similar to BERT.
3.Masked Language Modeling Objective:
- GPT-1 utilizes a masked language modeling (MLM) objective similar to BERT's. In this objective, a certain percentage of tokens in the input sequence are randomly masked, and the model is trained to predict the masked tokens based on the surrounding context.
4.Unidirectional Training:
- Unlike BERT, which uses bidirectional training, GPT-1 employs unidirectional training. It processes the input sequence from left to right, predicting each token based only on the tokens preceding it, similar to a traditional autoregressive language model.
5.Loss Function:
- Compute the loss for each predicted token using a softmax function over the vocabulary. The loss is then backpropagated through the network to update the model parameters.
6.Optimization:
- Utilize optimization algorithms such as Adam to update the model parameters based on the computed loss. Adjust learning rates, warmup steps, and other hyperparameters to optimize training performance.
7.Fine-Tuning:
- Optionally, fine-tune the pre-trained GPT-1 model on task-specific data using supervised learning. This involves initializing the model with pre-trained weights and fine-tuning the parameters on a downstream task such as text classification or language generation.
8.Evaluation:
- Evaluate the trained GPT-1 model on held-out validation and test datasets to assess its performance on the target task. Use metrics such as perplexity, accuracy, or F1 score depending on the specific task.
9.Iterative Training:
- Iterate the training process, adjusting hyperparameters, data preprocessing techniques, and model architecture as necessary to improve performance.
By following these steps, GPT-1 can be trained from scratch to learn contextual representations of text and perform well on a variety of language understanding tasks.
Conclusion:
Yet, employing Transformers presents its own set of hurdles. They demand substantial computational resources, extensive datasets for effective learning, and can sometimes overfit to the data at hand. Nevertheless, dedicated researchers are tirelessly addressing these challenges, striving to enhance Transformers' capabilities and address their limitations.
Looking ahead, Transformers will continue to propel NLP and adjacent fields to greater heights. Their applications will span diverse domains, encompassing language translation, text generation, sentiment analysis, and content summarization. As we venture further into the realm of AI, Transformers will remain at the forefront, reshaping our technological landscape and unlocking novel avenues for comprehending and harnessing language in the digital sphere.



Comments
Post a Comment